Our last ImpHash post covered the basics of what ImpHash is and how it can be leveraged for various DFIR use cases. One example is when a file hash is unknown and uploading content to a 3rd party malware scanning provider is prohibited. The ImpHash value will enable you to find matching bad files even if file content varies to some degree. Having said this, ImpHash has several limitations that users should be aware of.
In this post, we will cover the following ImpHash limitations:
- Works only on PE files
- Generic PE Import Tables
- Attackers can force an ImpHash value
Jump to…
ImpHash Refresher
Works Only on PE Files
Generic PE Import Tables
Original Files and Trojan Version Look The Same
Attackers Can Force an ImpHash Value
Conclusion
ImpHash Refresher
As a quick reminder, the basic goal of an ImpHash is to find Windows PE files(EXE, DLLs, etc.) that are similar. ImpHash focuses on files that claim to depend on the same libraries and functions.
The basic algorithm is:
- List out the PE file imports
- Make them lower case
- Calculate the MD5 of that list
Two files that have the same imports will have the same ImpHash, even if the other parts of the file are different.
The basic goal of using ImpHash in DFIR is that if someone can’t upload a file for analysis to an online malware scanning service, they could at least query for its ImpHash value to see if other files with the same ImpHash have been previously identified as being malicious. As we’ll discuss a bit below, this works great if other files with that ImpHash are either all good or all bad.
Works Only on PE Files
Within the goal of fuzzy matching all kinds of malicious code, one big disadvantages to using ImpHash is that it only works on PE files and as a result only helps with Windows based investigations. Traditional content based hashing (ex. MD5 and SHA256) and modern fuzzy hashing techniques (ex. SSDEEP and TLSH) are generally applied to all file content and are not file format specific. As a result, they work on all operating systems and are not limited to a specific file type. You can read more about these malware hashing techniques in a fantastic blog post by GData here.
The impact is that there are other file formats besides PE files that deliver malicious content. ImpHash will not help find variations of malware delivered in:
- Powershell scripts
- Office documents
- PDF files
- LNK files
Having said this, import hashing, as a general concept, can be applied to more than Windows PE files. The most notable are:
- TelfHash: An import hashing technique used on Linux ELF executable files. The main difference between ImpHash and TelfHash is that the imports are hashed using TLSH instead of MD5. As a result of the fuzzy hashing, hashes that are similar in value represent import tables that are also similar. You can read more about ELF files and the TelfHash implementation here.
- SymHash: An import hashing technique used on Mach-O executables found on Mac systems. Its implementation is similar to ImpHash with no major deviations. You can read more about Mach-O file format and the SymHash algorithm here.
- VBA_ImpHash: An import hashing technique for Office files that contain VBA imports. Its implementation is similar to ImpHash with no major deviations. You can read more about the project and its implementation here.
While these additional import hashing techniques help to expand the scope in which import hashing can be used, it should be noted that only TelfHash has picked up traction within the community as it is the only one, of the above three, integrated into VirusTotal and Malware Bazar.
Generic PE Import Tables
Another limitation of ImpHash is that some executables do not have unique import tables. This can happen based on how they were made or because an attacker is trying to blend in.
The impact is that some ImpHash values have “high match counts”, which means that 100s – 1000s of unique binaries have the same ImpHash, but many of them are completely unrelated. As a result, ImpHash matching effectively becomes useless because some percentage of the files could be good and some other percentage could be bad. Conclusions can’t be drawn from these hashes using only the ImpHash.
The problem stems from focusing on hashing just the import table. The only conclusion we can state for certain when finding matching ImpHash values is that the two files have identical import tables. Beyond that we make an educated guess and infer that two binaries have similar functionality based on our knowledge of what import tables represent. This works out great in scenarios where imports are large and unique but become less interesting as import tables shrink or are a standardized set of imports based on how an exe is built.
The following are a few scenarios where Import table are less interesting:
- .Net executables
- Go executables
- Packed executables
- Executables with a few standard imports
- File infector viruses
Generic .Net Executables
.Net is an open-source cross-platform framework for making applications. PE files that are made from .Net will generally have only 1 PE File import as seen in Figure 1. The import is for a .Net library, which will then use a .Net import table to load dependencies. As a result, ImpHash values will not vary among .Net applications even though they may have completely different behavior.
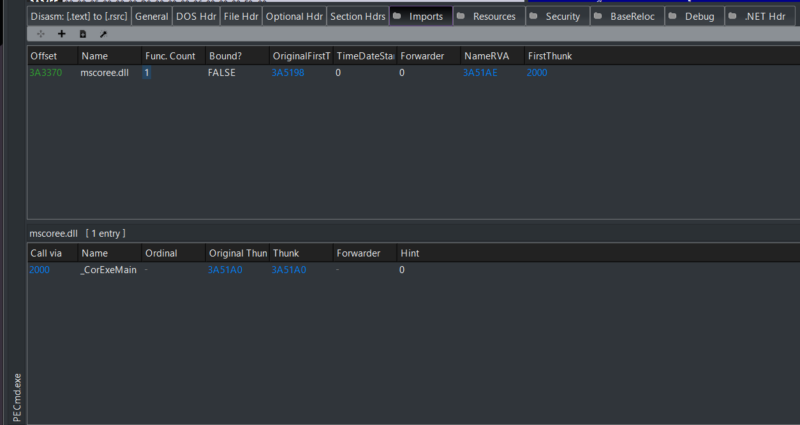
Figure 1: Example of PE imports for a PECmd.exe (.Net application)
The two documented .Net ImpHash values to be aware of are:
- f34d5f2d4577ed6d9ceec516c1f5a744 (import _CorExeMain)
- dae02f32a21e03ce65412f6e56942daa (import _CorDllMain)
A different import hashing technique must be used to find meaningful matches across .Net applications. Luckily this problem has already been solved by folks at GData. They created an import hashing technique called TypeRefHash. It works by targeting .Net specific import data stored in the TypeRef table instead of the PE import data. This allows for a more unique and meaningful match when comparing .Net binaries. You can read more about how TypeRefHash works here. You can find similar files using TypeRefHash on both VirusTotal and Malware Bazar.
Generic Go Executables
Go is a programming language developed by Google and, like .Net, many of its PE files have the same ImpHash values. But, it’s because Go binaries generally don’t have external dependencies and instead have copies of all the code it needs. This makes the import table less interesting and as a result ImpHash less useful. From our testing on a small sample set of go binaries we observed only functions from KERNEL32.dll being used.
Unlike .Net, there are more than 2 possible ImpHash values that Go binaries will have. The biggest factor that influences a Go executable’s ImpHash value is the version of Go used to build the exe. Simple and complicated programs will have the same ImpHash if they are compiled with the same version of compiler.
Figure 2 shows the import table for a complex Go binary compiled using Go version 1.22. Its ImpHash value is c2d457ad8ac36fc9f18d45bffcd450c2.
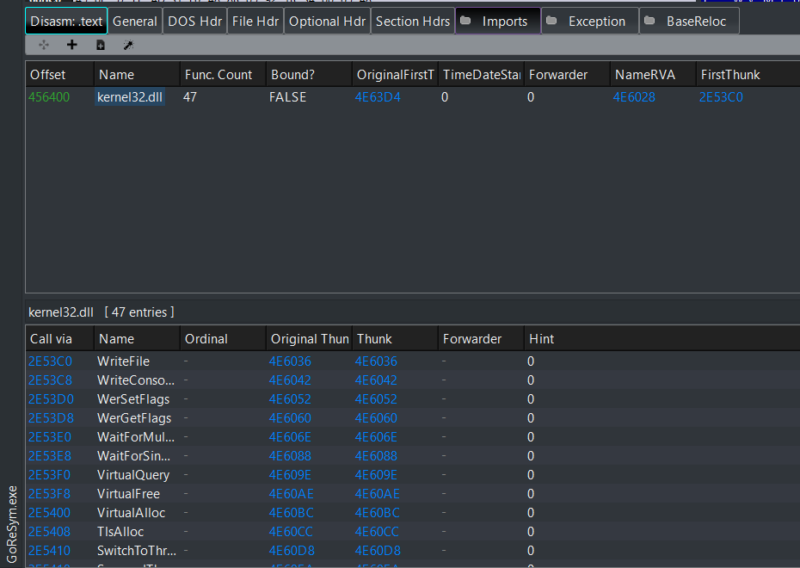
Figure 2: Example of PE imports for GoReSym.exe
Figure 3 shows a simple hello world program compiled with the same Go version 1.22. They both have the same imports and ImpHash value.
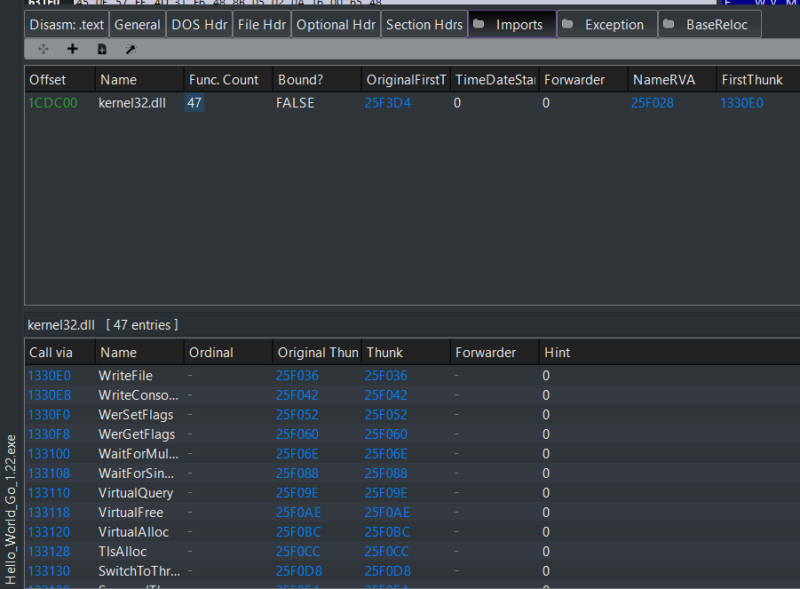
Figure 3: Example of PE imports for Hello_World compiled with Go 1.22
Figure 4 shows the same simple hello world program from figure 3, except now compiled using Go version 1.13. The ImpHash value has changed as the imports have changed.
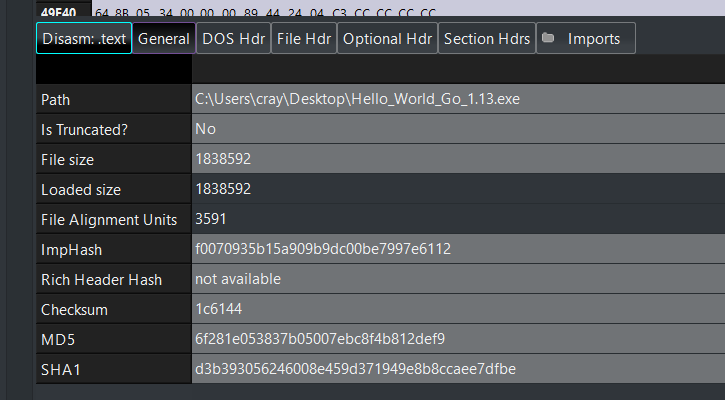
Figure 4: Example of ImpHash value for Hello_World compiled with Go 1.13
We can also find Snatch Ransomware that has the same ImpHash (because they used the same complier). This demonstrates how Go ImpHash values are not unique enough to use.
With all of this said, here are a few of the Go ImpHash values to look out for.
- C2d457ad8ac36fc9f18d45bffcd450c2 (Go version 1.22)
- F0070935b5a909b9dc00be7997e6112 (Go version 1.13)
- 167344a4df394fbba605fc972e41437a (Go version 1.15)
Note: this is not a complete list as we did not download every version of Go to check the ImpHash of our hello world program.
With Go malware on the rise, due to its cross platform support, it’s important to have a way to uniquely identify such binaries. Folks at NextronSystems decided to tackle this problem with the creation of GImpHash, A Go specific import hashing technique to support a more meaningful matching for Go Binaries. You can check out more details on the Go format and its import list from Mandiant here and GImpHash calculation details at NextronSystems` github here.
Generic Packed EXEs
Packed exes are another example of where ImpHashing falls short. The goal of “packing” an exe is generally to decrease its size on disk by compressing the PE file and launching it via a wrapper program. From an attacker’s perspective, packing makes it more difficult to analyze an exe and it has the added benefit of changing the content based hash as well as the ImpHash value.
In our testing with UPX, the packed executable will depend on the same DLLs as the original, but not all of the functions are listed. This results in a more generic ImpHash.
Below we have the import table for an executable that is used in Cyber Triage. Figure 5 shows over 100 imports listed, making this a good candidate for an ImpHash comparison.
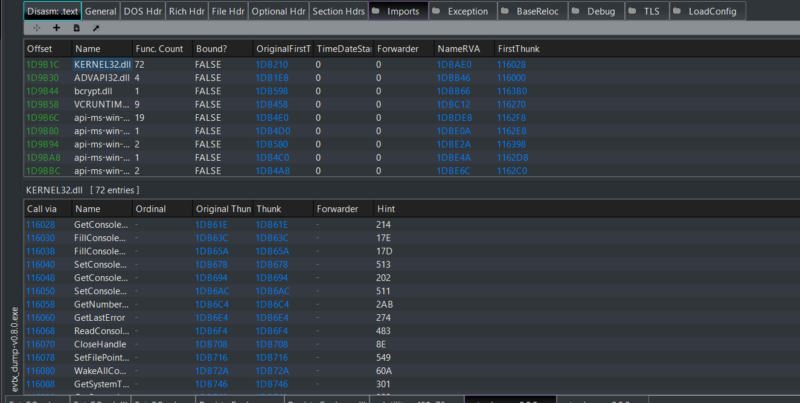
Figure 5: An example of an unpacked binary (evtx_dump-v0.8.0.exe)
However, after we run the UPX packer on the binary we see that the imports have significantly decreased. Each dll will have at most 1 function aside from the 4 in KERNEL32 which is needed by the packer to unpack the original binary into memory.
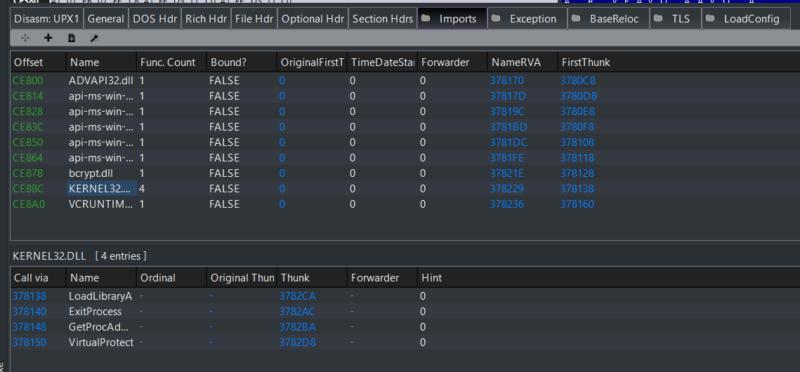
Figure 6: An example of a packed binary (evtx_dump-v080_packed.exe)
As a result, packed executables that depend on the same libraries, but different functions, will have a significantly higher chance of having the same ImpHash value.
Simple Programs With Few Imports
The number of imports and dependencies for a program is related to how complicated the program is and what it needs to do. Any binary that has a small number of imports will likely be a bad candidate for ImpHash, especially when the imports are from common Windows DLLs.
Simple programs may have collisions with other simple programs, even if the functionality is different.
Programs With No Imports
Some PE files have no imports. They may truly not depend on anything or the code may explicitly locate and load its dependencies once it starts to run.
The ImpHash for an empty import table will be d41d8cd98f00b204e9800998ecf8427e. This is not useful to correlate on.
Recorded Future has a post using this ImpHash value for a remote access trojan. It presumably loads libraries after it runs. We have also seen empty import tables for drivers and boot code across standard Windows systems.
Original Files and Trojan Version Look The Same
Attackers will sometimes take legitimate programs, such as cmd.exe, and add malicious code to them. If they can trick the user into running them or they replace the local copy of the program, then they now have persistence on the system.
If the malicious changes that were made did not change the import table, then both the good and bad versions have the same ImpHash.
We recently saw this with cmd.exe. On a system we were analyzing, cmd.exe had an:
- ImpHash of 272245e2988e1e430500b852c4fb5e18
- SHA256 of badf4752413cb0cbdc03fb95820ca167f0cdc63b597ccdb5ef43111180e088b0.
It was the authentic Windows cmd.exe signed by Microsoft.
But, it’s ImpHash also matched many bad files such as this Expiro Virus sample on VirusTotal. Expiro is a file infector virus that injects itself into a PE file without altering the import table.
As a result, many files infected with file infector viruses will show up as both good and bad making good files look potentially bad at first glance.
Attackers Can Force an ImpHash Value
Another scenario that ImpHash users should be aware of is ImpHash manipulation. This is where a threat actor defines the imports in such a way that the ImpHash value will not match the expected related malicious files.
There are a few reasons why an attacker might want to modify a files ImpHash:
- Make the file look like a known good tool to blend in
- Make the file look like a known bad tool used by a different group. This can be used to mislead attribution to another ATP group for example.
- Make the file’s ImpHash unique to have no matches. However, having a unique ImpHash makes it possible to do correlation across multiple hosts to find outliers.
At the time of this writing we are unaware of any groups or tools that alter binaries to evade ImpHash based detections but it is a possibility that users should be aware of.
There are two approaches to manipulating a file’s ImpHash value:
- Modifying source code
- Modifying PE header
Modifying Source Code
The first approach requires access to the source code of a file which means a threat actor must be able to obtain the source code, modify it, and build the exe to manipulate the ImpHash value. There are a few different approaches that one can take to modify source code such that the ImpHash value changes but functionality stays the same.
Source code manipulation can involve the following:
- Load methods at runtime (remove import entries)
- Introduce new dlls or methods (add import entries)
- Change order of methods used (reorder import entries)
Loading methods at runtime is the most limiting and time intensive method of the three options. This technique can be used to remove entries from the import table. The basic idea is that instead of directly using an API like NetUserAdd, to create an account, you can use LoadLibrary and GetProcessAddress to dynamically load the method which will result in NetUserAdd not showing up in the import table. You can read more about this here.
The second and third approaches are much easier to implement but still require some work. Introducing new DLLs and methods will result in new ImpHash values, while the third approach is to adjust code in such a way that the order in which methods are used is changed. Combining all three methods allows an attacker to add, remove, and reorder entries in the import table to mirror an ImpHash of another file.
Modifying PE Header
Modifying a files PE header directly has a huge advantage over code manipulation in that no source code is required. Its disadvantage is that it requires a higher level of skill and knowledge to manipulate PE headers in such a way that the order of imports can be changed without breaking the exe. We are unaware of any tools that automate this process for a threat actor so it seems less plausible than modifying the source code. However, there is a research team that has outlined an approach for how this can be done. You can read more about it here.
How Cyber Triage Deals With These Quirks
Despite the above scenarios, ImpHash still provides value in situations when the file can’t be uploaded.
To account for these issues, Cyber Triage does the following:
- Always match based on file content hash first. It’s far better to get results from a SHA256 match on content vs a match based on import tables.
- Always upload file content for unknown files whenever possible. Upload is better than ImpHash.
- If the file’s ImpHash is one of the generic hashes (.Net, .Go, empty hash), then do not do a lookup and provide user feedback. It is too generic.
- When we get a list of matching files via ImpHash, we:
- Look up the first 200 based off each files SHA256 content based hash to see if they are scored as good or bad.
- Identify the unique malware family names associated with any ones that were scored as bad
- Score the file as suspicious if 5 or more matches come back as bad. This allows the user to know there are bad files associated with the file they are interested in and a more in depth analysis of the file can be performed.
We mark files as suspicious instead of bad because of the potential for the previously described false positives.
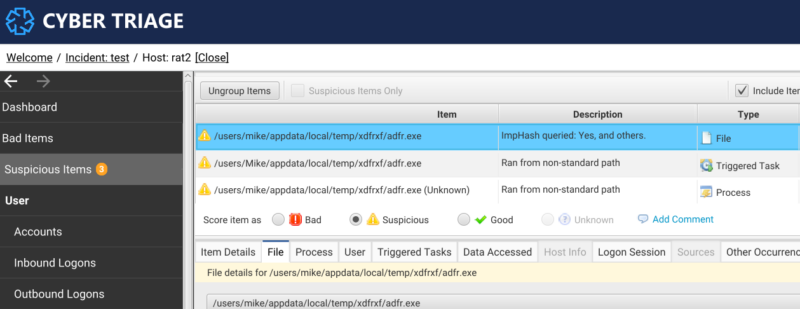
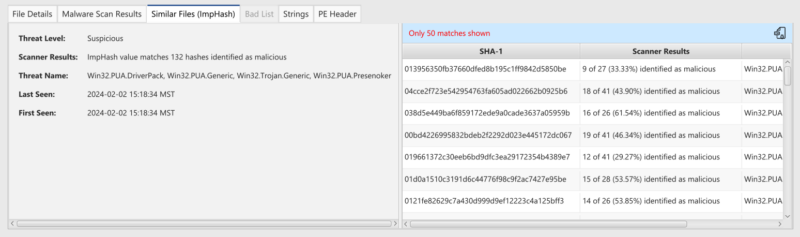
The user can see the scores in the ImpHash table below.
Conclusion
In summary, ImpHashing can be invaluable to DFIR investigations. However, it’s important to understand when ImpHash will not provide value. Scenarios that involve exes that are either not PE files or are PE files but have import tables that are too small and not unique are the biggest issues with ImpHash. Exes that are packed or are made from .Net or Go are generally not good candidates for ImpHash matching. While ImpHash itself may not fit every scenario, the idea of import hashing can be implemented to provide more unique values in such scenarios as we have seen in several import hashing methods inspired by ImpHash.
If you are looking to speed up your investigations with features like ImpHash, then try Cyber Triage. You can download a free one week trial version here: https://www.cybertriage.com/download-eval/
References:
General ImpHash/general hashing
- https://cloud.google.com/blog/topics/threat-intelligence/tracking-malware-import-hashing
- https://www.gdatasoftware.com/blog/2021/09/an-overview-of-malware-hashing-algorithms
Defeating ImpHash
- https://scythe.io/library/breaking-ImpHash
- https://malcomvetter.medium.com/defeating-ImpHash-fb7cf0183ac
Go
- https://github.com/NextronSystems/gImpHash
- https://cloud.google.com/blog/topics/threat-intelligence/golang-internals-symbol-recovery/
.Net
- https://www.gdatasoftware.com/blog/2020/06/36164-introducing-the-typerefhash-trh
- https://joseliyo-jstnk.medium.com/typeref-hasher-the-ImpHash-solution-for-samples-in-net-9aad14502bbf
ImpHash libraries
- https://github.com/erocarrera/pefile (python)
- https://pkg.go.dev/github.com/malwaredb/ImpHash#section-readme (Go)
TelfHash
- https://github.com/trendmicro/telfhash
- https://documents.trendmicro.com/assets/pdf/TB_Telfhash-%20An%20Algorithm%20That%20Finds%20Similar%20Malicious%20ELF%20Files%20Used%20in%20Linux%20IoT%20Malware.pdf
Mach-O SymHash